Brownian Motion
Building intuition for Brownian motion by deriving its marginal distribution from a discrete-time random walk.
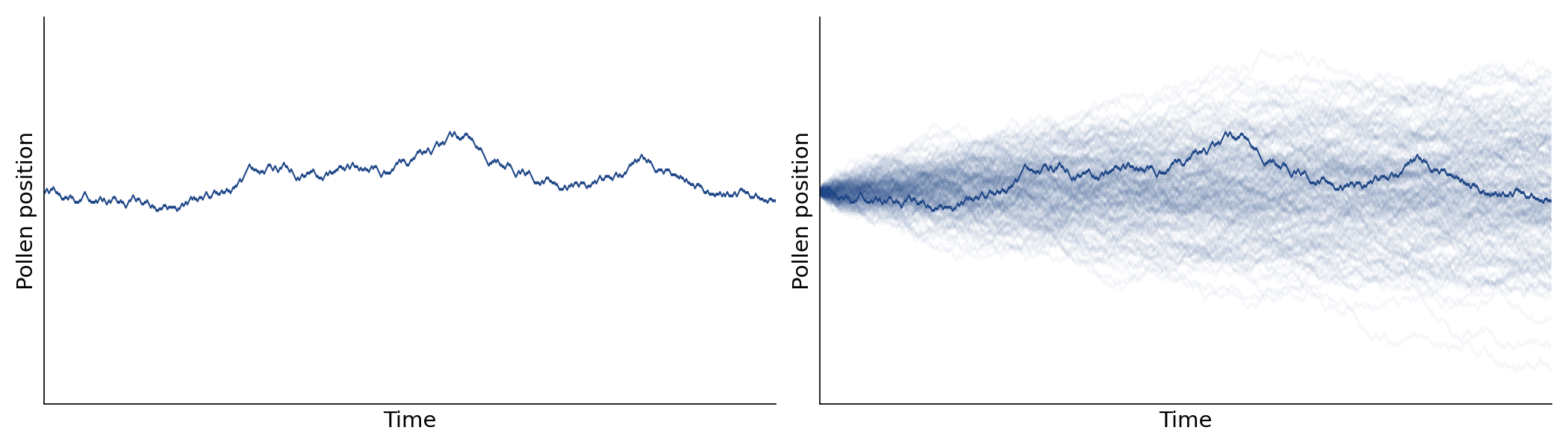
Imagine that a pollen particle is suspended in a glass of water. If we were to observe and record the vertical position of the particle over time, we would find that its movements were random. And if we were to plot this position, we’d get a jagged path through time (Figure , left). This path would be just one of many possible paths, and if we were to repeat this observational experiment many times, we would not expect to see the same path again.
Given this randomness, how can we reason about this phenomenon? Can we say anything interesting or useful about the particle? For most of human history, this was a seemingly impossible task. A key insight, a conceptual pillar in probability theory, is to separate what actually happened (Figure , left) from other possible outcomes (Figure , right). This approach allows us to reason about the world through counterfactuals: what are all the possible paths the pollen could have taken? How likely is each path? What can we say about the distribution of outcomes?
This understanding of the pollen particle as a random process is a deep idea, and it took many decades and scientists to understand. The phenomenon was first observed in the 1830s by the Scottish botanist Robert Brown. Brown used a microscope to observe pollen particles suspended in water, and to his surprise, he saw the particles moving! At first, he thought this meant that the pollen particles were alive, but he tested and then rejected this hypothesis by observing the same effect with particles that he was convinced were inanimate, such as glass powder, minerals, and even pulverized fragments of the Egyptian Sphinx (Góra, 2006)! For roughly half-a-century, the phenomenon remained a mystery, although it became known as Brownian motion.
Then starting in 1905, Albert Einstein published a series of papers in which he hythesized that the pollen particles were moving because they were being bombarded by invisible molecules in the liquid (Einstein, 1905). In the following year, the Polish physicist Marian Smoluchowski independently published essentially the same theory (Von Smoluchowski, 1906). At the time, this theory was controversial, because the idea of molecules was not yet widely accepted. However, using statistical mechanics, Einstein and Smoluchowski were able to make testable predictions about the behavior of the particles, and another scientist, Jean Baptiste Perrin, verified the model a few years later (Perrin, 1909). And since Einstein’s breakthrough work, Brownian motion has been widely studied and more deeply understood. In the mathematical community, Brownian motion was formalized by Norbert Wiener (Wiener, 1923), and thus Brownian motion is often referred to as a Wiener process, particularly by mathematicians.
The goal of this post is to better understand Brownian motion. Brownian motion is an important concept because it can be used to model many phenomenon, from particles suspended in liquids to the prices of stocks. Ultimately, we’ll reconstruct the marginal distribution of our pollen particle at any given point in time. As we will see this, this is the normal distribution. This deep connection means that we can make mathematically precise probabilistic statements about a completely random process.
Random walks
Let’s begin with a simplified model of our pollen particle in discrete time. This is a stochastic process called a random walk. In the next section, we’ll extend this to continuous time, which is Brownian motion.
Imagine we can discretize time and then observe a single discrete “tick” on the clock. What happens to the pollen particle during this one tick? In our simple model of the world, we’re going to imagine that we flip a coin, not necessarily fair, and that the pollen particle moves up or down the same amount based on the outcome of that coin toss. The coin toss models the fact that the pollen particle is being randomly bombarded by water molecules and thus its position at the next time point is random. So the pollen particle cannot stay in place; after one tick of the clock, it moves up or down.
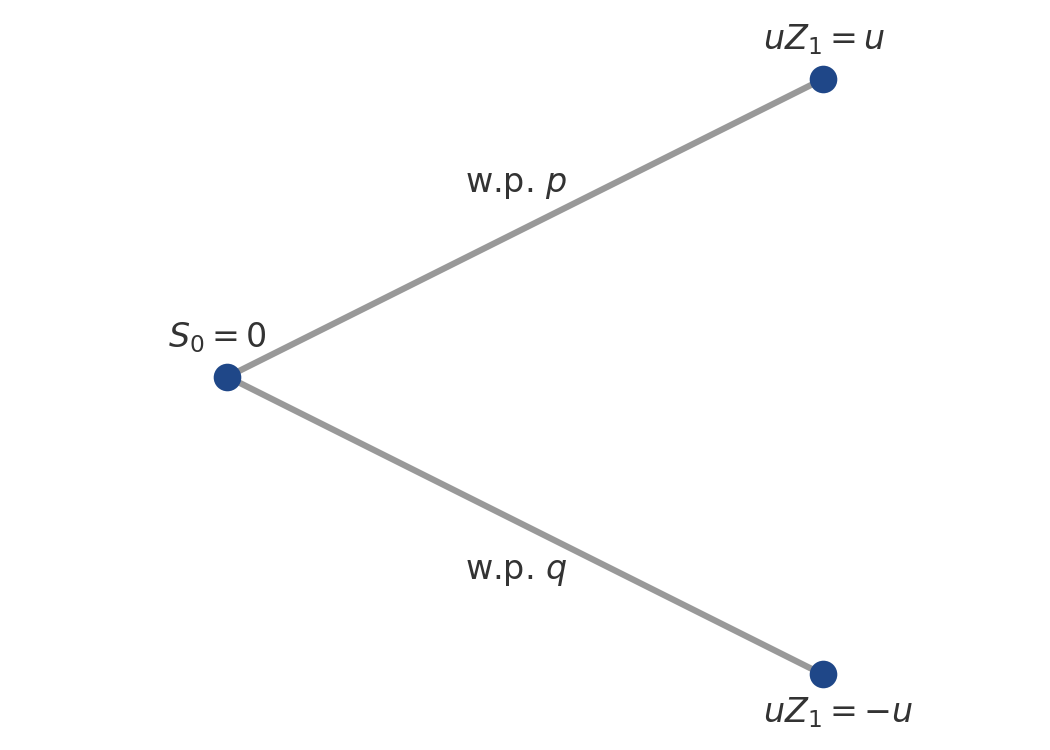
Formally, let be the particle’s initial position (non-random), and let be a univariate random variable denoting the vertical position of the pollen particle after one tick. We assume that the initial position is zero (), since this makes our calculations and notation easier and since it is simply a vertical shift in the final path. So we flip a coin with bias , where is the probability of heads () and is the probability of tails (). If the coin is heads, then the pollen particle moves up , and if the coin is tails, then the pollen particle moves down (to ). Let’s denote the outcome of each coin flip as a random variable , taking values in . Then the position after a single coin flip is (Figure ).
Now consider the position after time steps. At each time point , we flip a coin, which we assume is independent of all other coin tosses, to discover whether the pollen particle is displaced up or down from its current position. Then is simply the sum
Since each is random, is also random.
Clearly, as we repeatedly flip our coin, the set of possible locations of the pollen particle expands linearly with . We can visualize all these possible locations as a directed graph or tree, sometimes called a binomial tree (Figure , left)—we’ll explain the name in a moment. The tree layers (vertical slices) are zero-indexed, and so the root node occurs at time . Each node is a possible location, and the -th layer is all possible locations by time . The directed edges (left to right) are valid moves of the pollen particle. A path in this binomial tree is a sequence of steps which starts at the tree’s root (left-most node) and continues right at each time step until it reaches a leaf node (right-most node). A valid path is one that always moves left-to-right, from root to leaf. A valid path cannot, for example, move straight down at the same time point or move backwards.
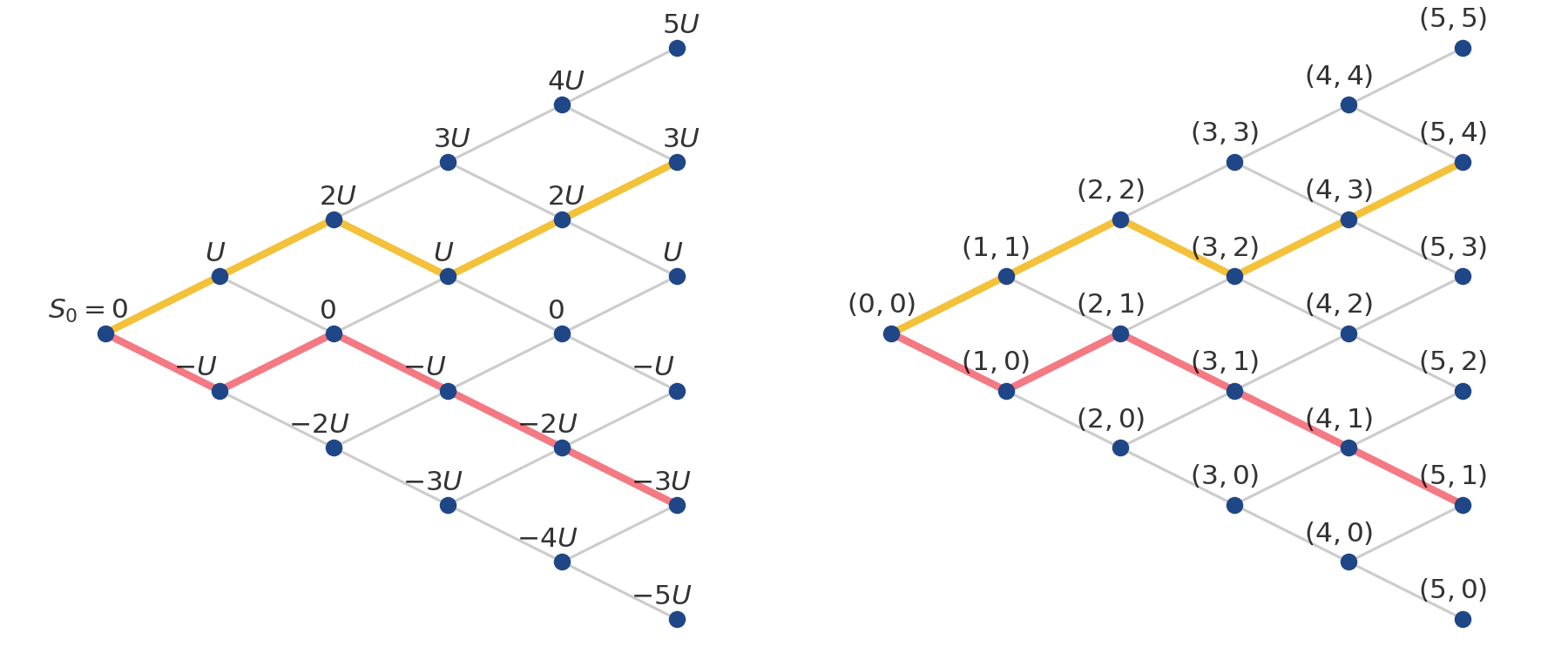
To help us identify nodes, let’s introduce the counting number , which indexes the leaf nodes, taking values in . Like the time index , the number is a zero-based index. Let’s denote the bottom leaf node with and the top leaf node with . To illustrate this, I’ve visualized the tree with the nodes labeled with tuples (Figure , right).
Now that we understand this simple, discrete-time model for our pollen particle, let’s tackle our motivating question: which outcomes (leaf nodes) are most likely? Any given path is random, but can we say something about the distribution of outcomes?
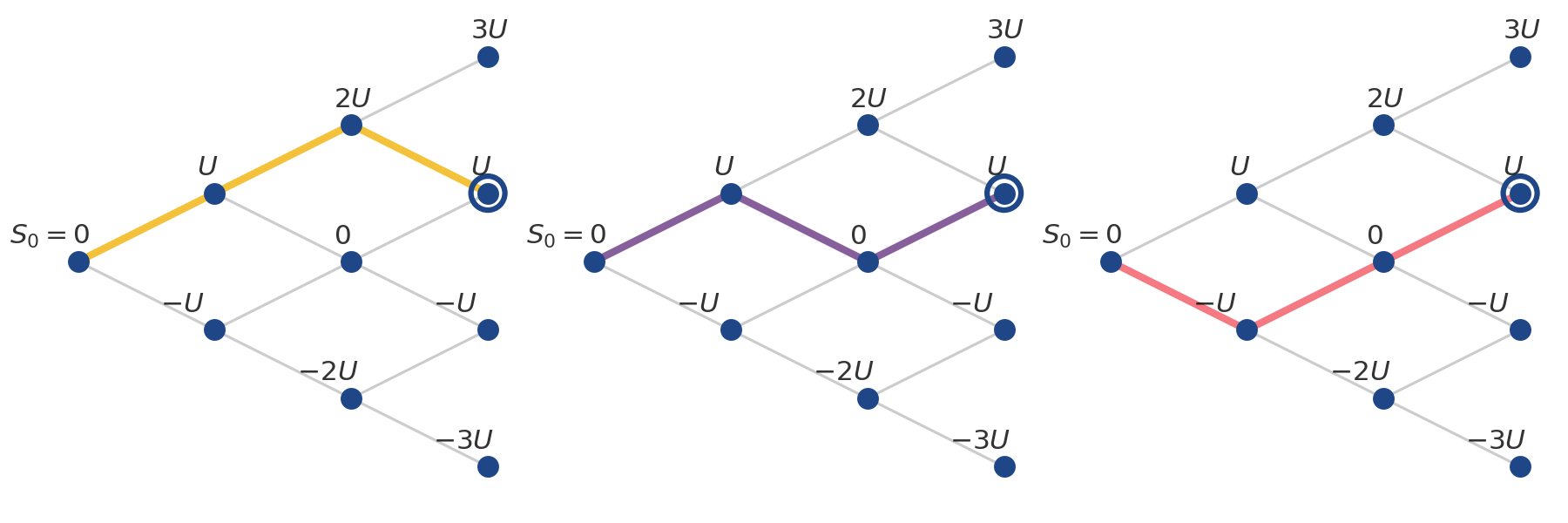
To start, let’s compute the probability of arriving at the highlighted leaf node in Figure . This is really the probability of arriving at a given node , which in turn is really the probability of flipping heads in coin tosses. Let’s use for this random variable. Arriving at this node requires that we flip two heads and one tails. The probability of this is
However, there are three ways flip two heads in three coin tosses,
which is another way of saying that there are three paths to the highlighted node. Since each path is a mutually exclusive outcome, we compute our desired probability by summing the probability of all outcomes in Equation by the number of paths:
For example, if , then this probability would be .
To compute this probability in general, we just need a way to compute the number of ways to get successes or heads in trials. Since order matters, the number of ways to pick heads from coin tosses is
First, we can choose any of coin tosses to be a heads. Then we can pick any of coins tosses to be heads. And so on, until we have heads. (The last pick is completely constrained.)
However, this overcounts the possible paths. For example, this does not distinguish between and , where the subscript denotes the -th coin toss. So we need to divide the permutation in Equation by the number of ways we can order elements in a -sized set. This is factorial. Putting this together, we see that the number of ways to get to each node in the binomial tree is
This number in Equation is often called the binomial coefficient, pronounced “ choose ”, and is denoted as
Putting it all together, the probability of arriving at the -th node in the -th layer of a binomial tree is
The fact that these probabilities sum to one is just a trivial application of the binomial theorem. See A1.
Computing the mean and variance of is relatively straightforward. We can view as the sum of independent Bernoulli random variables, so
The mean of each is , and the first two moments are easy to compute:
For the variance calculation, we use Bienaymé’s identity and the fact that are independent. The distribution of was first discovered by Jakob Bernoulli and is called the binomial distribution after the binomial terms implicit in choose —again, see A1—and hence the “binomial tree.”
Of course, is the distribution on the number of heads in coin tosses, while we’re more interested in the location of the pollen particle. But there’s a simple relationship between the two. The location is simply the number of up moves (), minus the number of down moves (), scaled by the size of the move . In other words, it is:
Since and are non-random, the events and are identical. So we can say
So the location of our pollen particle by a given layer is determined by the distribution of a random variable with the probability mass function (PMF) in Equation . While and have the same probabilities, they clearly have different moments. The first two moments of are:
In the special case in which , then
We can explore this distribution by plotting the function for various parameterizations (Figure ). Note that while is binomially distributed and while and have the same probability function, is not binomially distributed. That’s because the binomial distribution only has support over the non-negative integers. It’s a distribution over repeated coin flips. But has support over the negative numbers. I don’t think the distribution of has a name, but speaking loosely, it is essentially a binomial distribution mean-centered at zero.
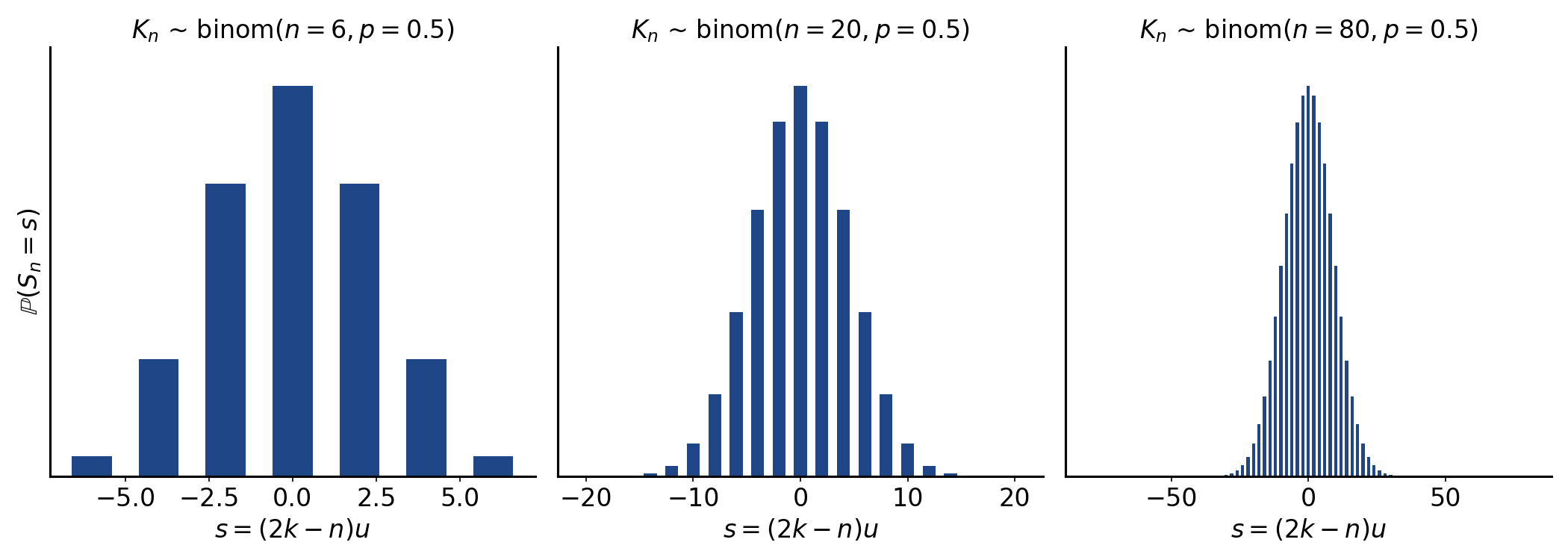
And another way to visualize this is to imagine larger and larger binomial trees (Figure ). The distribution for the locations for are the distributions in Figure .
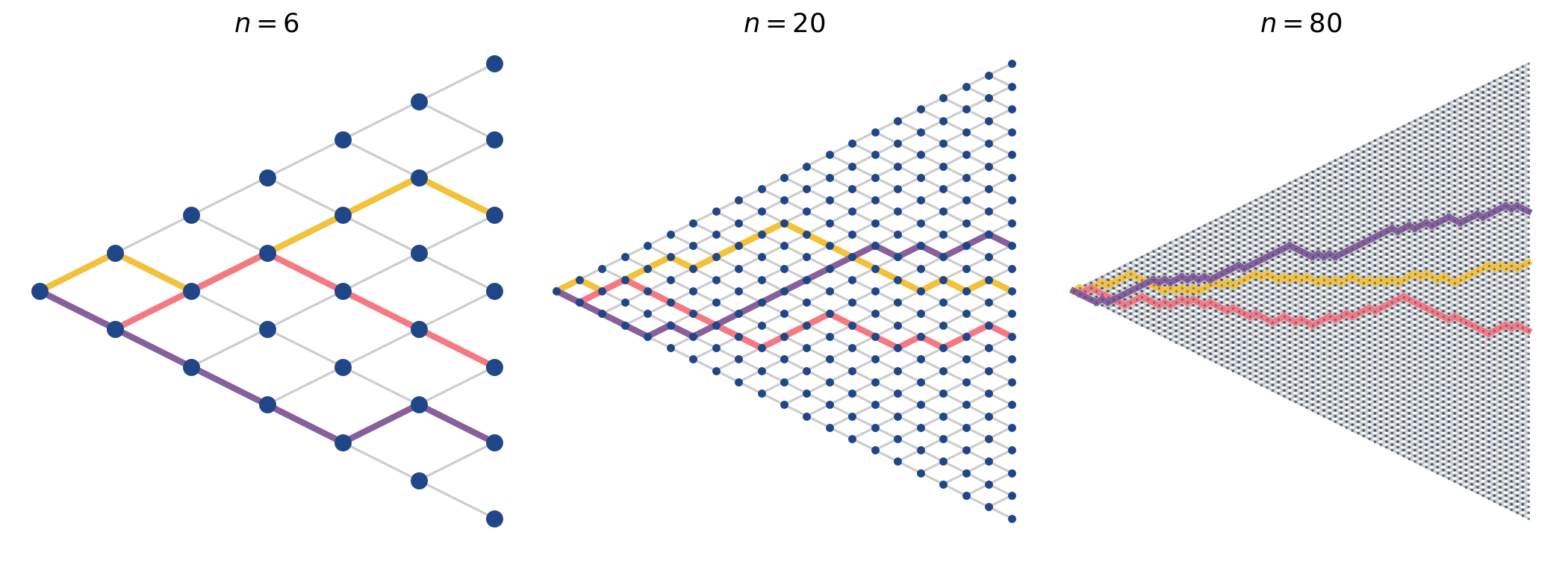
To summarize so far, we have done something remarkable. We have modeled the motion of a completely random particle, and yet we can say something concrete and precise about its distribution of locations over time.
To do this, however, we had to assume that time was discrete. So the natural next question is: what’s the distribution of our process in the continuous-time limit? At this point in our story, it is not far-fetched to guess that it’s the normal distribution. De Moivre proved the De Moivre–Laplace theorem, the earliest version of a central limit theorem (CLT), in 1738, so roughly a hundred years before Robert Brown observed Brownian motion. So scientists and mathematicians already knew that a sum of independent and identically distributed random variables converge to a Gaussian. The key insight in the development of Brownian motion was to realize that the bombardment of a pollen particle could be modeled as such as a sum.
Convergence of a rescaled random walk
So now let’s imagine what happens when the molecular bombardments on our pollen particle increase in number but decrease proportionally in impact. So we have more bombardments but they move the pollen particle less per bombardment. This rescaling is critical, or else the variance of our process would explode. Put in physical terms, if we increased the number of bombardments of our pollen particle but did not scale down the size of the move, the pollen particle’s moves would grow implausibly large.
To formalize this, let’s first fix so that . We’ll handle the asymmetric case later. Now suppose that there are bombardments per unit of physical time , so for any fixed amount of physical time , we can model the location of our pollen particle as
The notation just indicates flooring to an integer since is a positive real number. And we need to scale with , and so we set . If we take , then we get a continuous-time limit of a random walk:
So again, we hold physical time fixed, and we make our binomial tree finer and finer (larger for fixed ). If we remove the grid of the binomial tree which clutters the visualization, and just visualize paths for finer and finer , we can create visualizations similar to Figure but for much larger (Figure ).
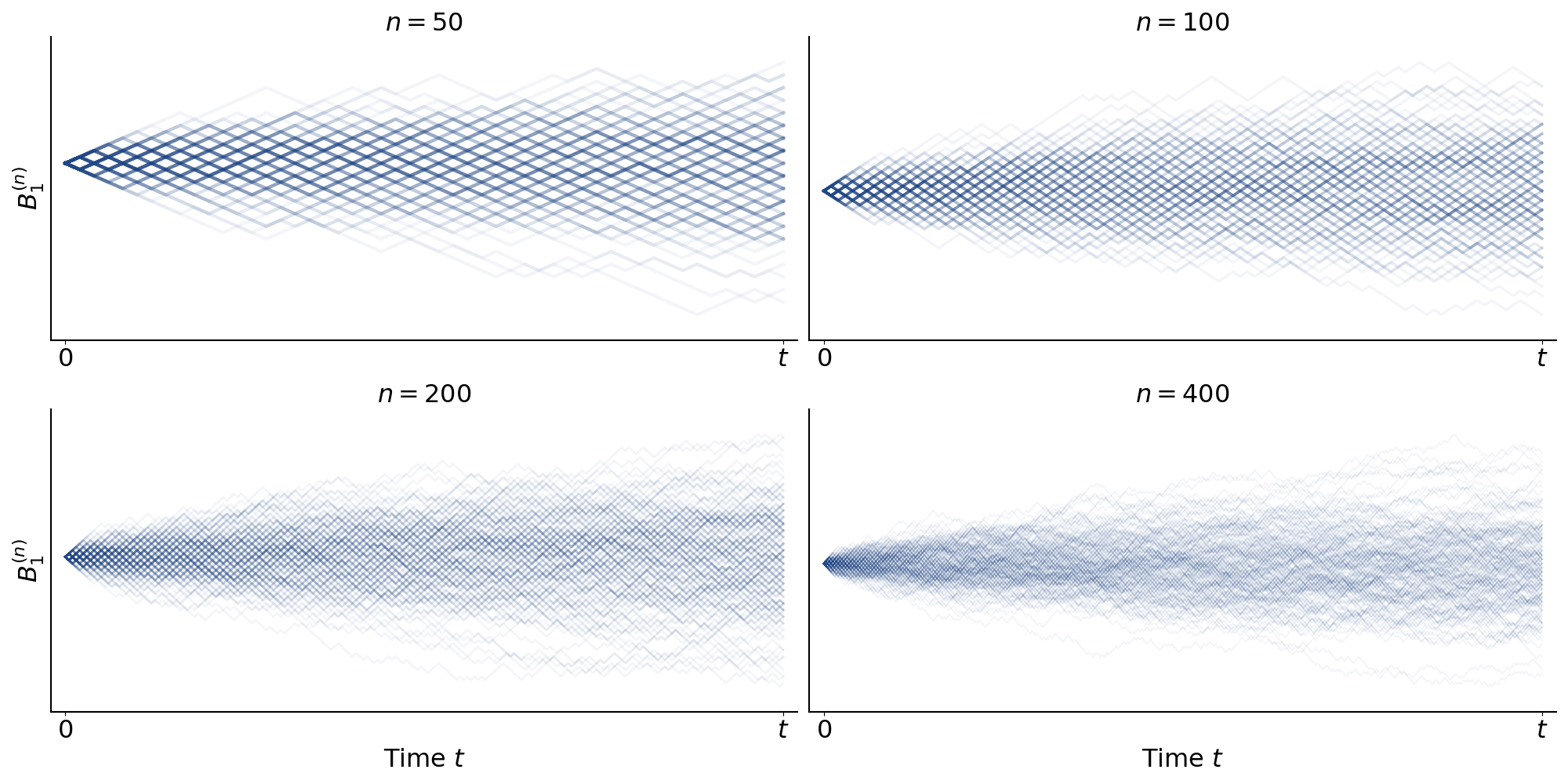
Now we can ask the same question we asked in the discrete-time case: after physical time , what is the distribution of our pollen particle’s position? As we observed above, it must be a normal distribution! Here, the insight is not that the binomial distribution converges to the normal distribution—again, this was known a hundred years before Robert Brown’s observations. The insight is that by modeling the continuous-time limit of a random walk as in Equation , this rescaled random walk converges to a normal distribution .
Let’s see this a bit more formally. The De Moivre–Laplace theorem states that a properly standardized binomial random variable converges to the normal distribution. In our notation, with , and the theorem states:
Now observe that is essentially this standardized quantity up to rescaling:
By De Moivre–Laplace, we can say:
And as , we can see that the prefactor converges to :
Since the standardized binomial converges in distribution to and the prefactor converges to the constant , we can see that
That’s it! As an aside, I think that in a modern treatment, we would invoke Slutsky’s theorem to arrive at Equation . Slutsky’s theorem states that if a sequence of random variables converges in distribution and is multiplied by a sequence converging to a constant, then the product converges in distribution to the constant times the limit.
The geometric interpretation of this is that the marginal distribution after time is simply the normal distribution (Figure ).
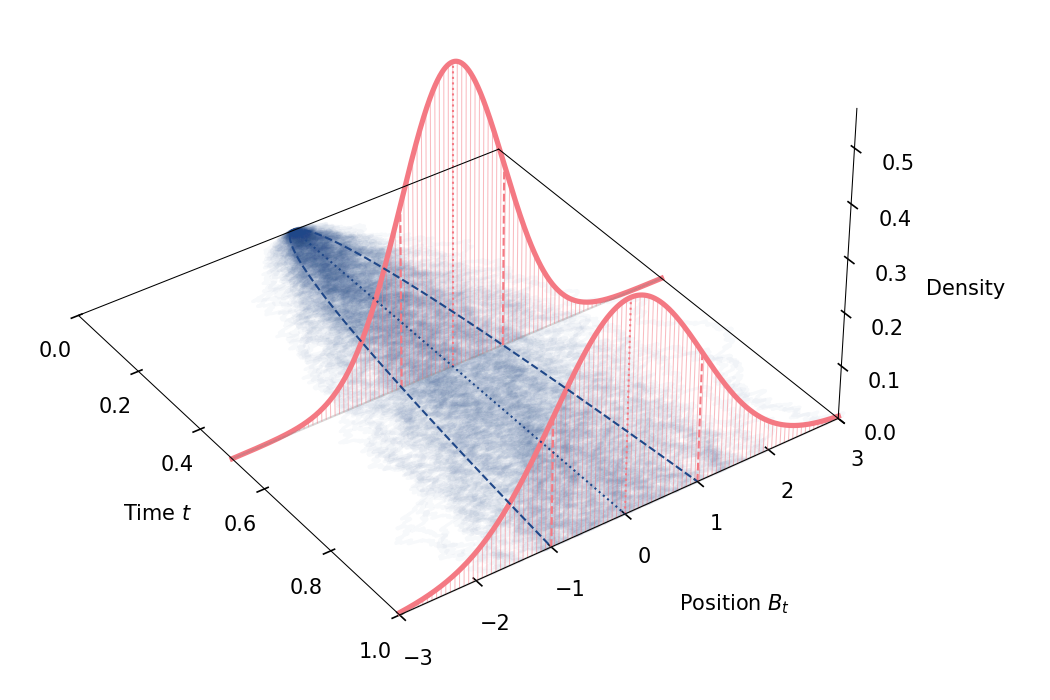
Now that we see the simplest version of the derivation in its entirety, we can make two important adjustments. First, notice that our bombardment factor has no physical meaning. The denominator just ensures convergence, and so this bombardment has unit scale. But we can introduce a parameter which captures the physical scale of the bombardment. Concretely, let
It’s easy to see that this will flow through the derivation in Equation and give us
But I think the more interesting adjustment is adding a drift parameter . Of course, we could just shift our Brownian motion directly:
But this has no physical meaning for our process. It’s just an arbitrary shift, not a drift. A richer way to approach this is to encode it directly into the bias of our coin flip. Intuitively, if we flip a biased coin (so ), then the position our pollen particle will drift over time (Figure ).
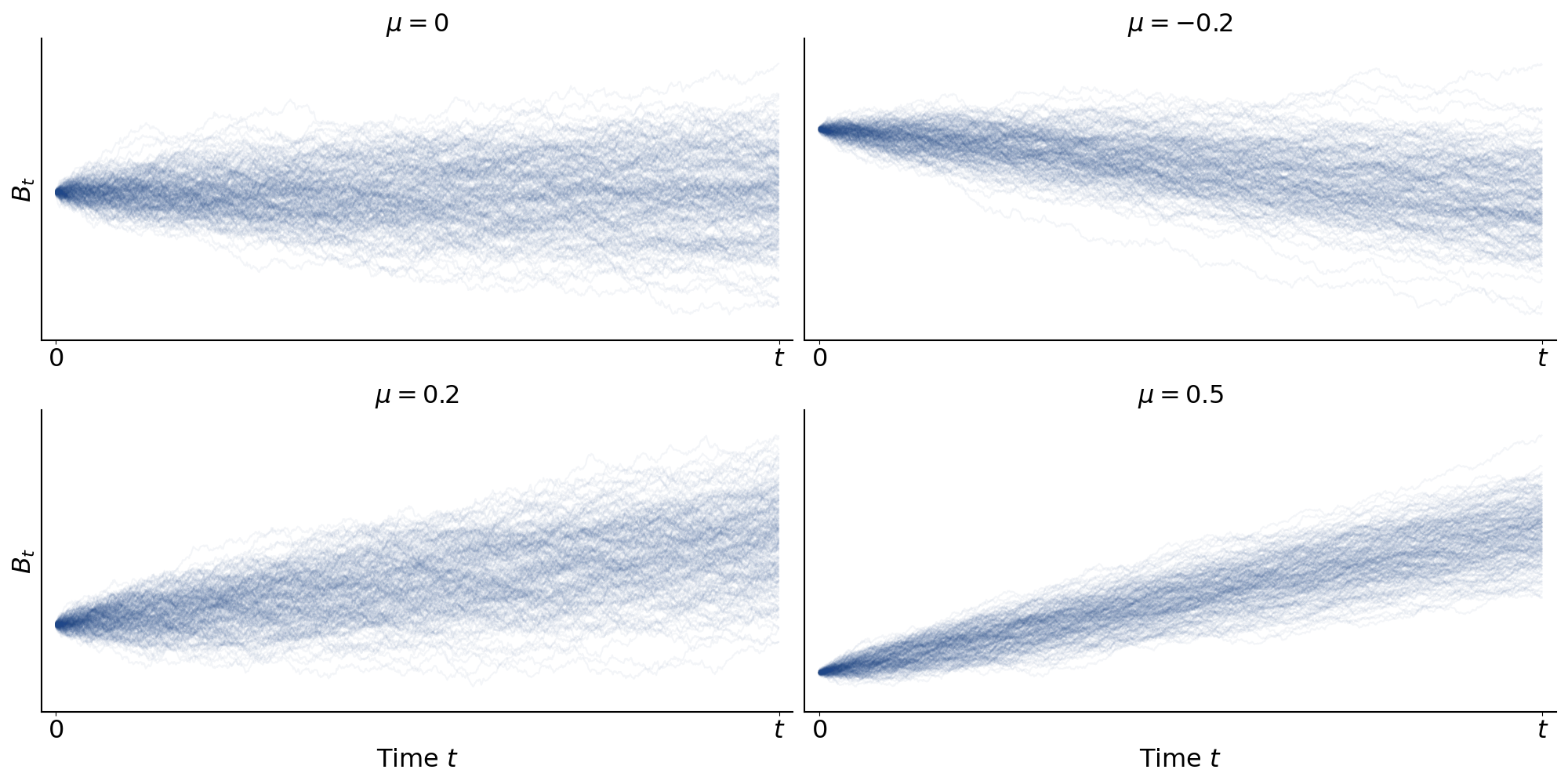
However, there’s a problem with this approach: since is constrained to , then is constrained to , and thus the mean of our Brownian motion is constrained to :
A more elegant approach is to make a function . However, we cannot naively do this, since our drift could explode as . So we need to normalize by . Consider this definition for our bias parameter, now :
Intuitively, the factor is the precise rate at which the bias of our coin has to vanish as we increase the number of bombardments per unit of physical time . So the mean of each is
and so the mean of our process—let’s denote it as since it is no longer standardized—converges to as :
Putting these two adjustments together—one for the drift and one for the size of the bombardment—we can see that the general result is non-standard Brownian motion:
Alternatively, we could simply rewrite the main derivation (Equation ) using and as defined in Equations and respectively. This is arguably the more elegant derivation, since we construct the marginal distribution from the ground up. See A2 for this derivation.
Note that this isn’t a proof that the rescaled random walk converges to Brownian motion as a process. That requires more advanced mathematics such as Donsker’s theorem. Rather, it’s a claim about its marginal distribution at any fixed time . But I think this provides amazing intuition for what Brownian motion really is without requiring much beyond elementary probability.
Conclusion
I still remember sitting in class for a course on probability and random process and watching the professor churn through the algebra to produce the insight in Equation . It felt surprising and then obvious. The normal distribution is everywhere precisely because it is the limiting distribution for sums of independent and identically distributed random variables. We can shift or scale our random walk. We can make it asymmetric. It doesn’t really matter. We’ll still converge to a normal. And in my mind, this derivation builds good intuition for other properties of Brownian motion. For example, we can say that Brownian motion is a martingale or that it has stationary Gausian increments. The mathematics needed to make these claims precise might require some work, but the basic intuition is encoded in the derivations and visualizations above.
Appendix
A1. Binomial theorem
The binomial theorem is the following identity, which holds for any non-negative integer power :
This is easy to prove by induction. One can trivially check that the base case holds. And the inductive step is as follows:
If we write each sum and explicitly, it’s clear that we have overlapping terms:
Collecting the like terms, we get:
Finally, we can use the following identity to collapse bracketed binomial coefficients:
And we can rewrite the non-overlapping terms in terms of since
This completes the inductive step:
Finally, the fact that the binomial distribution normalizes—discussed around Equation —is simply a direct application of the binomial theorem for and .
A2. Convergence with mean-centering and scaling
Let be defined as
Then clearly
Let’s redefine as the following sequence:
We can write this as:
Finally, it’s clear that the prefactor converges to as :
while the last term converges to as :
And since
then again by Slutsky’s theorem, we know
So converges to a normal distribution with drift and volatility .