Moving Averages
I discuss moving or rolling averages, which are algorithms to compute means over different subsets of sequential data.
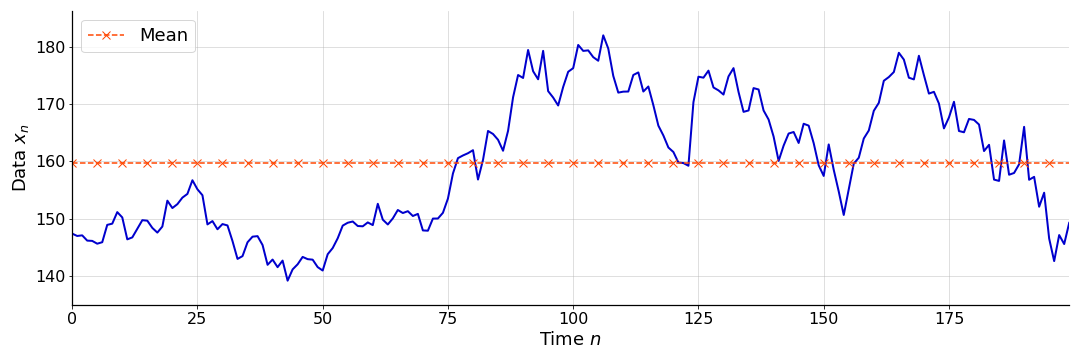
A moving average, sometimes called a rolling average, is a sequence of averages, constructed over subsets of a sequential data set. Moving averages are commonly used to process time series, particularly to smooth over noisy observations. For example, consider the noisy function in Figure . If these data represents a time series, we may not be interested in a single point estimate of the mean (red dashed line). Instead, we may be interested in a sequence of mean estimates, constructed as the data becomes available. By having an average that “moves”, we could construct a new sequential data set that is a smoothed version of the input data.
While moving averages are fairly simple conceptually, there are details that are useful to understand. In this post, I’ll discuss and implement the cumulative average, the simple moving average and the weighted moving average. I’ll also discuss a special case of the weighted moving average, the exponentially weighted moving average.
Cumulative average
Consider a sequential data set of observations,
These data do not need to be a time series, but they do need to be ordered. For simplicity, I will refer to the index as “time”. Thus, at time , the datum has just been observed, while the datum is the next observation. These are useful ways of talking about the problem setup, but the operations being discussed could be applied to any sequential data, such as a row of pixels in an image.
Perhaps the simplest way to make the point estimate in Figure “reactive” to new data is to compute a cumulative average (CA). In a CA, the sample mean is re-calculated as each new datum arrives. At time point , the CA is defined as
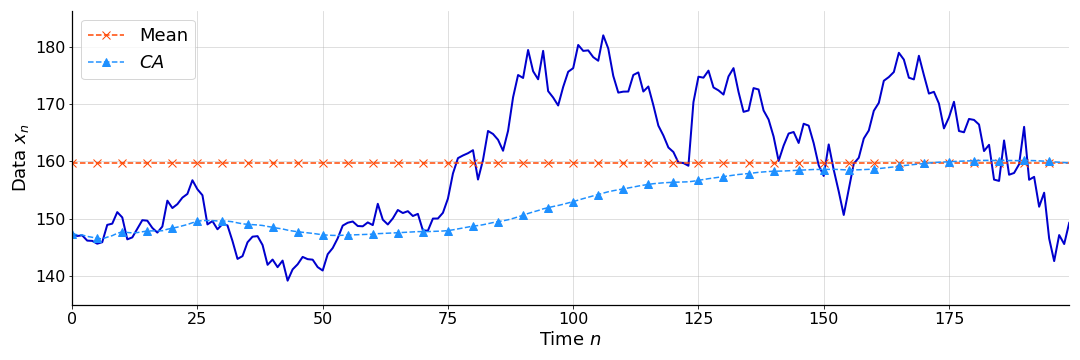
The effect is a sequence of mean estimates that account for increasingly more of the data. See Figure for an example of a simple CA applied to the data in Figure . Clearly, at time point , the mean of the entire data set (red dashed line) is equal to (right-most point of blue dashed line).
We can implement a CA in Python as follows:
def ca(data):
"""Compute cumulative average over data.
"""
return [mean(data[:i]) for i in range(1, len(data)+1)]
def mean(data):
"""Compute mean of data.
"""
return sum(data) / len(data)
Notice, however, that re-computing the mean at each time point is inefficient. We could simply undo the normalization of the previous step, add the new datum, and then re-normalize. Formally, the relationship between and is
This results in a faster implementation:
def ca_iter(data):
"""Compute cumulative average over data.
"""
m = data[0]
out = [m]
for i in range(1, len(data)):
m = ((m * i) + data[i]) / (i+1)
out.append(m)
return out
As we’ll see, this idea of iteratively updating the mean, rather than fully recalculating it, is typical in moving average calculations.
Simple moving average
While the CA in Figure is certainly an improvement upon a single average in Figure , we may want a sequence of estimates that are even more reactive. Look, for example, at the difference between the time series and the CA at . The time series is rapidly increasing in value, but the CA is slow to react. One way to make the CA more reactive is to compute the average over a moving window of the data, where “window” refers to the subset of data in consideration. In other words, we can “forget” old data.
At each time point , a simple moving average (SMA) computes the average over a backward-looking, fixed-width window. Let denote the window size. Then for each index , we want to compute
Note that based on the definition in Equation , the first elements in the sequence are ill-defined. We could define them in one of two ways:
Following the convention used by Pandas, I’ll define as undefined (or NaN).
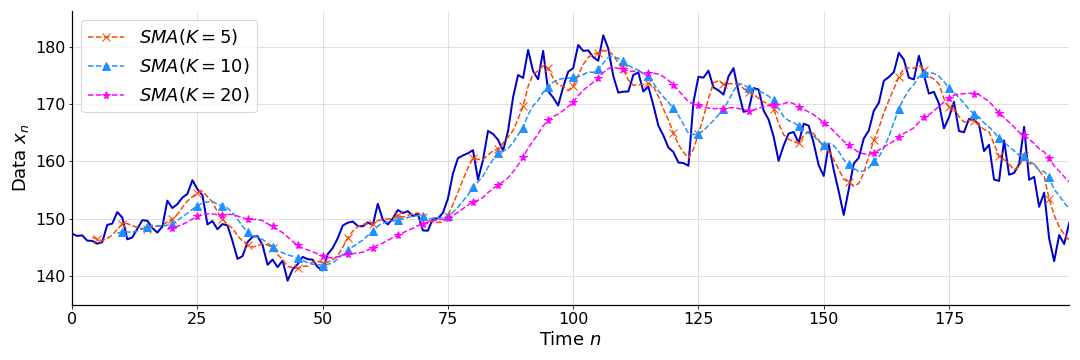
See Figure for an example of several SMAs with varying window sizes, applied to the noisy function in Figure .
In Python, a simple moving average can be computed as follows:
nan = float('nan')
def sma(data, window):
"""Compute a simple moving average over a window of data.
"""
out = [nan] * (window-1)
for i in range(window, len(data)+1):
m = mean(data[i-window:i])
out.append(m)
return out
However, there is a trick to computing SMAs even faster. Since the denominator never changes, we can update an existing mean estimate by subtracting out the datum that “falls” out of the window, and adding in the latest datum. This results in an iterative update rule,
In Python, this faster implementation is:
def sma_iter(data, window):
"""Iteratively compute simple moving average over window of data.
"""
m = mean(data[:window])
out = [nan] * (window-1) + [m]
for i in range(window, len(data)):
m += (data[i] - data[i-window]) / window
out.append(m)
return out
(Obviously, the code in this post is didactic, ignoring edge conditions like ill-defined windows.)
Weighted moving average
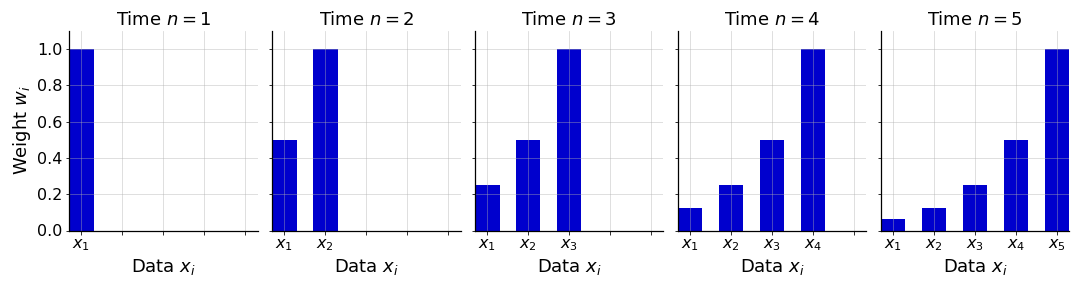
An obvious drawback of a simple moving average is that, if our sequential data changes abruptly, it may be slow to respond because it equally weights all the data points in the window. A natural extension would be to replace the mean calculation with a weighted mean calculation. This would allow us to assign relative importance to the observations in the window. This is the basic idea of a weighted moving average (WMA). Thus, each observation in the window has an associated weight,
and these are applied consistently (i.e. in the same order) as the window moves across the input. Formally, a weighted moving average is
Note that this definition is agnostic to the specific weighting scheme used, and that the number of weights can grow with the number of observations ( at each time point ).
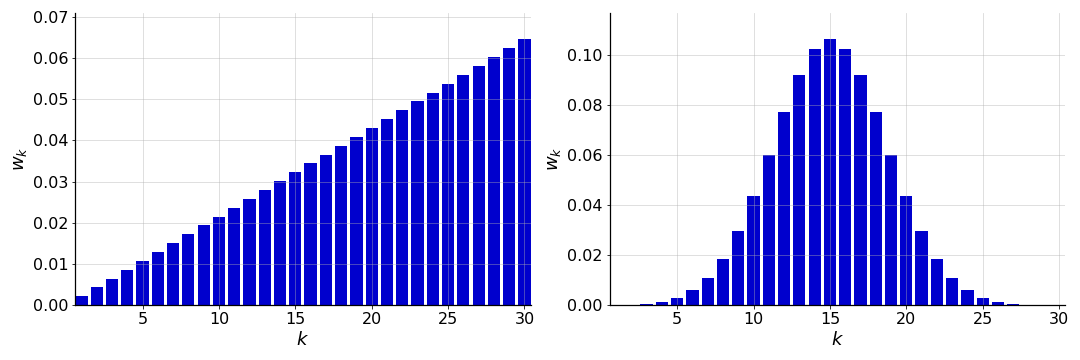
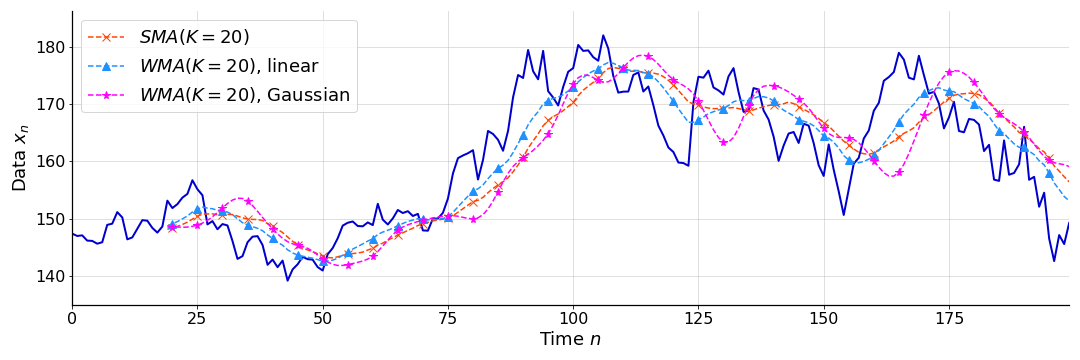
For example, we could use weights that emphasize the most recent datum, e.g. by decaying linearly with time (), or we could use weights that smooth the data, e.g. by applying Gaussian distributed weights or a Gaussian filter ( where is normally distributed). See Figure for examples of these weights.
See Figure for a comparison of a simple moving average and a weighted moving average with both linearly decaying weights and Gaussian filter weights, both applied to the function in Figure . We can see that the linearly decaying weights react more quickly to the signal than the SMA, and that the Gaussian weights smooth the function more.
In Python, a naive WMA can be implemented as follows:
def wmean(data, weights):
"""Compute weighted mean of data.
"""
assert len(data) == len(weights)
numer = [data[i] * weights[i] for i in range(len(data))]
return sum(numer) / sum(weights)
def wma(data, weights):
"""Compute weighted moving average over data.
"""
window = len(weights)
out = [nan] * (window-1)
for i in range(window, len(data)+1):
m = wmean(data[i-window:i], weights)
out.append(m)
return out
I call this “naive” because it treats the weights as a moving window, which is an unnecessary constraint. As I mentioned above, the size of the window can grow with the number of observations. As with an SMA, there are tricks to computing WMAs even faster using iterative updates. However, the algorithmic details depend on the choice of weights. We’ll see one iterative update rule with exponentially decaying weights (below).
Exponential moving average
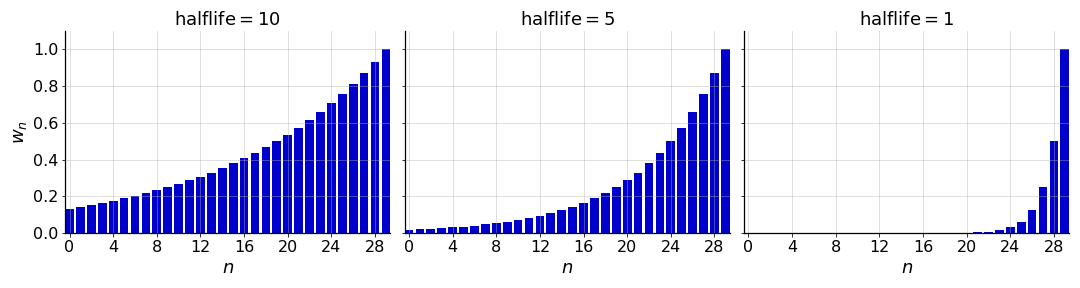
A poplar choice of WMA weights are ones that decay exponentially (Figure ). I have a couple ideas for why this choice is so common. First, much like linearly decaying weights (Figure , left), exponentially decaying weights emphasize the most recent data points and can be chosen to decay approximately linearly near the current observation. However, exponentially decaying weights handle older data more elegantly: rather than a datum going from weighted to unweighted (or weight zero) when exiting the window, each datum is assigned a weight that decays asymptotically toward zero. In practice, we can stop tracking the weights once they are sufficiently close to zero. Secondly, exponentially decaying weights can be parameterized in a few ways, giving the modeler several ways to think about how the smoothing occurs.
As a reminder, let denote the initial quantity. Then the exponentially decaying function can be expressed in the following parameterizations:
See my previous post on exponential decay as needed. Note that in my previous post, I denoted the decay rate as rather than . Here, I’ve switched to to match how I often see the parameter discussed in the context of EWMAs. Furthermore, is sometimes called a smoothing factor rather than a decay rate, since changing has the effect of smoothing (or not smoothing) the time series.
Given the various parameterizations, there are many ways we could implement EWMAs, and each parameterization lends itself to a different iterative updating scheme. Clearly, discussing each in turn would be too tedious. Thus, I’ll narrow the discussion in the following way: first, I’ll explain EWMA using the halflife parameterization, which is the most natural in my mind. I like halflives because they are in the natural units of the process (e.g. halflife in hours for data that is hourly). I won’t refine this much, though. Instead, I’ll switch to discussing EWMA using the rate parameterization (using ), which is how I see often see it discussed (e.g. see Wikipedia and Pandas source code).
Halflife parameterization
Recall that the halflife of exponential decay is the value in the domain at which the function reaches half of its initial value. Since exponential decay never reaches zero, the number of weights in an EWMA equals the number of observations so far (). Thus, let’s think of the weight (where indexes the data up until time point ) as a function of the observation . Using the halflife parameterization, the weight is defined as
Obviously, this equation depends on my notation. If you assumed that was assigned to the most recent datum, Equation would be different. See Figure for an example of a sequence of exponentially decaying weights.
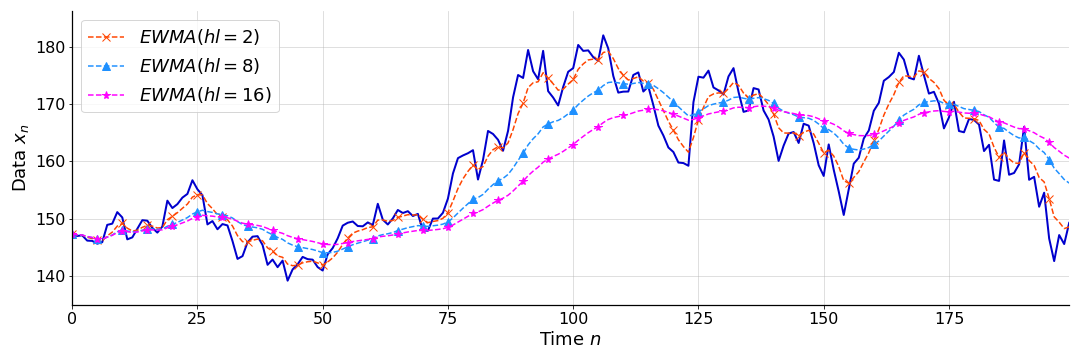
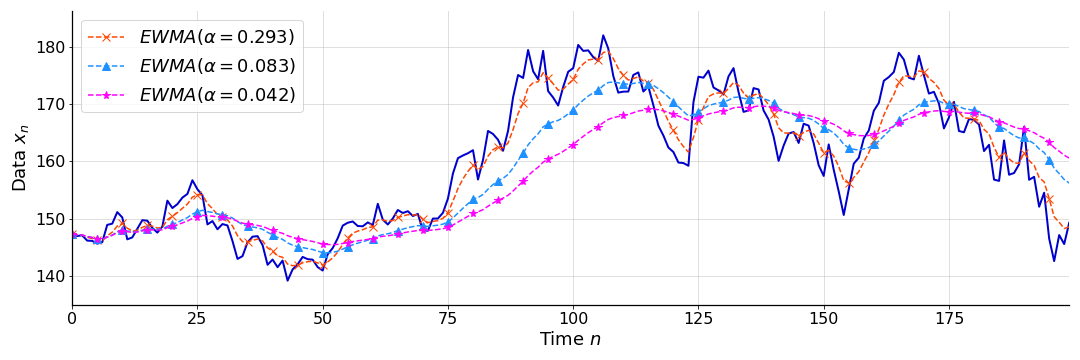
As I mentioned, in my mind, halflife is an intuitive parameter because it is in the natural units of the process. A shorter halflife means the EMA is more reactive to changes in data, while a longer halflife means that more historical data is considered for longer. So a bigger halflife means more smoothing. See Figure for a comparison of EWMAs with varying halflives, all applied to the function in Figure .
In Python, an EWMA can be implemented as follows:
def ewma_hl(data, halflife):
"""Compute exponentially weighted moving average with halflife over data.
"""
weights = [(1/2)**(x/halflife) for x in range(len(data), 0, -1)]
out = []
for i in range(1, len(data)+1):
m = wmean(data[:i], weights[:i])
out.append(m)
return out
Notice that I simply construct a set of exponentially decaying weights at the start, and then index into that set. This works for a subtle reason: since exponential decay is memoryless in the sense that the function decays as a fraction of its current quantity, the set of weights applied inside the weighted mean calculation (wmean) are always correct because they are normalized. If the un-normalized magnitude of the weights mattered, this implementation would not work.
Smoothing factor parameterization
Now let’s explore EWMAs in terms of the rate or smoothing factor . I think this parameterization is important if only because this is how many others think about and explain EWMAs. I’ll start by explaining what I’ll call the un-adjusted EWMA. This is an algorithm that approximates the exponentially decaying weights fairly well but is not technically correct, i.e. the weights do precisely exponentially decay. Then I’ll discuss the adjusted EWMA, which is simply the correct version of the un-adjusted approach. Why this terminology? I am simply borrowing from Pandas, which implements an EWMA with an adjust parameter.
To be clear, I’m not quite sure why the un-adjusted algorithm is discussed so often, since it technically incorrect and since both the halflife-parameterized algorithm and the adjusted EWMA are both easy to understand and correct. However, I’ve decided to discuss it simply since I have seen the un-adjusted formulation many times and never quite understood it. (When you see it, you should ask yourself why it is correct; in fact, it is not!)
Un-adjusted EWMA. A commonly discussed iterative update rule is the following,
Wikipedia cites the National Institute of Standards and Technology website, which in turn cites (Hunter, 1986) for this rule. We’ll investigate what Equation means and why it works in a moment. For now, let’s assume it is correct and just think about how to interpret it. (Hunter, 1986) has an interesting perspective. Let’s think of as the predicted value of the time series at time . Let’s denote this . Thus,
Now let’s rewrite the update rule in Equation as
In other words, the next predicted value in the time series is the current predicted value in the time series, plus some fraction of the error between what we observed and what we predicted. If , then we would not believe our predictive model at all. The next predicted value would be the current observation. This EWMA would simply reconstruct the original time series. (Hence why is a restriction.) If , then we would not trust our observations at all. The next predicted value would always be the initial value . (Hence why is a restriction.) Alternatively, we can think of the next prediction as a convex combination of the current observation and the current prediction.
Either way, to quote (Hunter, 1986), “determines the depth of memory of the EWMA”. See Figure for examples of EWMAs with parameters chosen to match the halflives in Figure . At the end, I’ll discuss this reparameterization from to .
Now that we have some intuition for this formulation, let’s ask ourselves the obvious question: how does Equation (or ) model a moving average with exponentially decaying weights? Let’s write down the formula for the first few data points:
Note that we can distribute the and generalize this to
Here, we can see why Equation approximates a weighted moving average with exponentially decaying weights. With the exception of the weight associated with the first datum , the -th weight is defined as
Note that we are computing the weighted mean on the fly, meaning that these weights must sum to unity. Using basic properties of geometric series, we can verify this:
So this approach is reasonable. However, the weight associated with the first datum is incorrect. It should be , yet it is only . For sufficiently large , this term should be close to zero. While the error is typically quite small, there is an error. An “adjusted” EWMA (discussed next) is simply the correct formulation. As I mentioned, it’s useful to understand the un-adjusted approach, because it comes up often, but in practice, I think there’s no reason not to just understand and use the adjusted approach.
Adjusted EWMA. The correct update rule is the following:
Here, we update each datum with the weight
And we normalize the calculation at each time point by dividing by the sum of the weights. It’s pretty easy to see that both the numerator and denominator in Equation can be updated recursively:
This gives us a fast, iterative algorithm to exactly compute an EWMA online. In my mind, Equation is very simple to reason about and implement.
In Python, an EWMA with smoothing factor can be computed as follows:
def ewma_alpha(data, alpha):
num = data[0]
den = 1
out = [num/den]
for i in range(1, len(data)):
num = data[i] + (1 - alpha) * num
den = 1 + (1 - alpha) * den
out.append(num/den)
return out
This is the code that is used to produce Figure .
Switching parameterizations
As a final comment, it’s useful to be able to switch to between the halflife and smoothing parameterizations. In my post on exponential decay, I showed that the smoothing factor is related to the decay parameter in the following way:
Later in the post, I also showed that halflife is related to decay in the following way:
Using these two equations, we can easily solve for in terms of or vice versa:
These operations are useful when you want to work in a particular parameterization that is not supported by a given EWMA implementation.
- Hunter, J. S. (1986). The exponentially weighted moving average. Journal of Quality Technology, 18(4), 203–210.