OLS with Heteroscedasticity
The ordinary least squares estimator is inefficient when the homoscedasticity assumption does not hold. I provide a simple example of a nonsensical -statistic from data with heteroscedasticity and discuss why this happens in general.
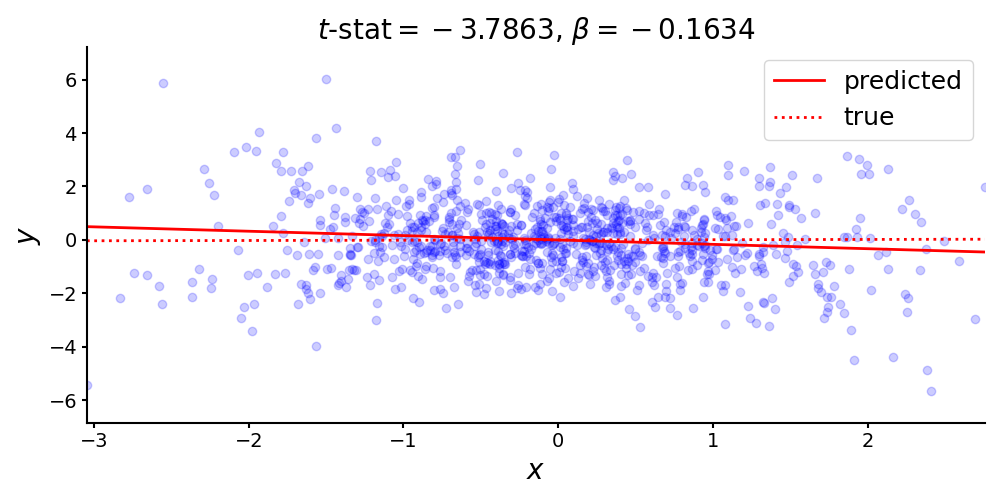
Consider this linear relationship with true coefficient and no intercept (Figure ):
from numpy.random import RandomState
rng = RandomState(seed=0)
x = rng.randn(1000)
beta = 0.01
noise = rng.randn(1000) + x*rng.randn(1000)
y = beta * x + noise
Let’s fit ordinary least squares (OLS) to these data and look at the estimated and -statistic:
import statsmodels.api as sm
ols = sm.OLS(y, x).fit()
print(f'{ols.params[0]:.4f}') # beta : -0.1634
print(f'{ols.tvalues[0]:.4f}') # t-stat: -3.7863
Remarkably, we see that the sign of the coefficient is wrong, yet the -statistic is large in magnitude. Assuming normally distributed error terms, a -statistic of indicates that our estimated coefficient, , is nearly four standard deviations from the null hypothesis (here, zero). (See my previous post on hypothesis testing for OLS if this claim does not make sense.) This is obviously wrong, but what’s going on here? The problem is in the noise term:
noise = rng.randn(1000) + x*rng.randn(1000)
Each element in the vector noise is a function of its corresponding element in x. This breaks an assumption in OLS and results in incorrectly computed -statistics. The goal of this post is to look at this phenomenon (heteroscedasticity) and some solutions in general.
Non-spherical errors
Recall the OLS model,
where is an -vector of response variables, is an matrix of -dimensional predictors, specifies a -dimensional hyperplane, and is an -vector of noise terms. We could include an intercept by adding a column of ones to . A standard assumption of OLS is spherical errors (see Assumption here). Formally, spherical errors assumes
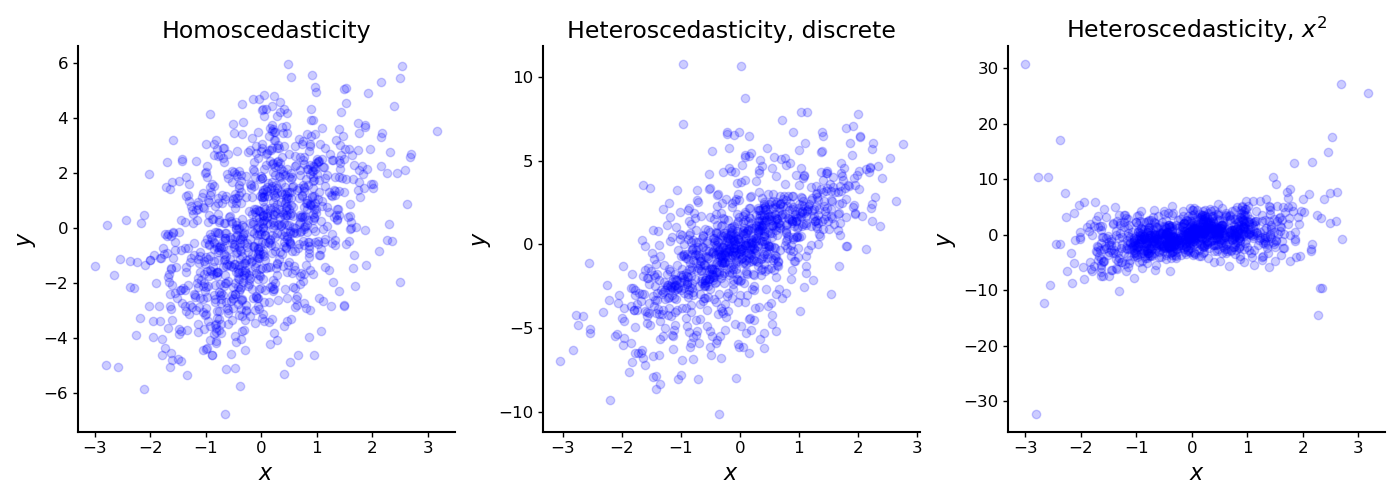
In words, all noise terms for share a constant variance (Figure , left). This assumption may be reasonable when our data are approximately i.i.d., but this is often not the case. Let’s look at the simple scenario in which this assumption does not hold: when the error terms are heteroscedastic.
In statistics, scedasticity refers to the distribution of the error terms. OLS assumes homoscedasticity, which means that each sample’s error term has a constant variance ( in Equation ). With heterscedasticity, each sample has an error term with its own variance. Formally, Equation becomes
There are multiple forms of heteroscedasticity. Consider, for example, data which can be partitioned into distinct groups. These types of data may exhibit discrete heteroscedasticity, since each group may have its own variance (Figure , middle). A real-world instance of discrete heteroscedasticity might arise when data is collected from multiple sources, such as if each city or province in a country is responsible for reporting its own census data.
Alternatively, consider data in which each datum’s variance depends on a single predictor. These data may exhibit heteroscedasticity along that dimension (Figure , right). For example, in time series data, variance might change over time. This type of heteroscedasticity was the source of our problems in the leading example.
A second challenge for OLS is when the error terms are correlated, inducing autocorrelation in the observations. Then Equation becomes
We could, of course, have both heteroscedasticity and autocorrelation, in which case the diagonal in Equation would be replaced with the diagonal in Equation . In this post, I will limit the discussion to only the first scenario, heteroscedastic errors.
Incorrect estimation with OLS
So what happens when we apply classic OLS to data with variance
instead of spherical errors. Here, is a positive definite matrix that allows for heteroscedasticity or autocorrelation. First, observe that the estimator from classic OLS,
is still unbiased, even with a generalized noise term:
This holds because we still assume that , if we still assume that while the errors can be heteroscedastic, their conditional expectation is still zero.
However, despite still being unbiased, the OLS estimator still has a problem. Deriving the OLS variance,
requires assuming homoscedasticity (see Equation here). Without this assumption, the correct variance would be
This follows immediately from plugging in into Equation in the previous post, and we cannot simplify it further without assuming some structure for the error terms.
The second problem is that is no longer an unbiased estimate of . Logically, this holds since there is no longer a single . Furthermore, the derivation for the unbiasedness of depends on homoscedasticity. (See Equation here.)
We can now see that this is why we estimated incorrect -statistics in the leading example. Recall that the -statistic for the -th coefficient of is
where is the hypothesized true value and the denominator is the standard error. (See my previous post for details.) Both the estimated variance and are incorrect without homoscedasticity being true. In fact, it’s impossible to know if the -statistic will be too large, too small, or correct without knowing more about .
Asymptotic behavior
Finally, let’s consider the asymptotic behavior of the OLS estimator. A standard assumption is that
for some positive definite matrix . This is a reasonable assumption because of the weak law of large numbers. The basic idea is that our data are “well-behaved” in the sense that they converge to their expected values. (See this post on OLS consistency for discussion.)
However, notice that (the middle term in Equation ) is more subtle. Without knowing anything about , there is no guarantee that will converge in probability to some matrix. However, even if we did assume this, that
for some matrix , then all we could say is that the OLS estimator converges in distribution to
But we cannot simplify the covariance matrix, and .
Summary
In short, without homoscedasticity, the nice properties of the OLS estimator do not hold, and inference using OLS on heteroscedastic data will be incorrect. There are a few solutions to this problem. The first is to use generalized least squares (GLS) if we do know the variance. This is because GLS is the best linear unbiased estimator when assuming generalized error terms. Another approach is to still use OLS but to use heteroscedasticity-robust standard errors instead of the usual standard errors. Finally, in some situations, we can use weighted least squares. I will discuss these topics in more detail in future posts.